🌘 AI Roundtables @lunar.dev
Thank You, Lunar Team
Before diving into all the AI insights: thanks Eyal Solomon (aka Luli, CEO) and Roy Gabbay (aka Gabbay, CTO), and Rotem (VP R&D), from lunar.dev for arranging these meetups and letting me be a part of what y’all are building. Leading the charge on AI thought leadership is hard with so much BS in the air.
I definitely learned a ton, met cool folks from the industry, and even had fun. So thanks! 🙏

Alright, enough schmoozing. Let’s get to the good stuff. I wrote down these notes during the meetup, so obviously I might have missed some things; if you were there and want to add something, please reach out.
Also, I’m not mentioning the names or companies, since these were exclusive events. But trust me, the folks who attended are “the industry” in their respective fields.
Reflections on Two #lunardev AI Roundtable Meetups
I recently attended not one, but two AI roundtable meetups arranged by Lunar (and hosted in some VC offices: Mizmaa and Pitango). Between the jokes, snacks, and occasional mild existential panic, I walked away with a deeper appreciation of just how messy (and exciting) this whole generative AI scene can be. In this post, I’ll recap the highlights, share some of the biggest challenges the groups grappled with, and offer a few insights into where I think AI landscape might be heading next.
“The real money might be in building tools for the tool makers.”
A sentiment shared by multiple attendees, echoing the new generation of AI-savvy developers.
Meetup #2: Deep Dives into LLMs and Agentic Systems

Attendees and Their Missions
Alright, so picture this; I’m invited to a roundtable meeting. It’s filled with super strong folks from different verticals, all doing hardcore AI in production: security, industrial, data-driven startups, stealth-mode innovators, and more. Everyone brought a unique problem or perspective:
- A developer at a data-driven startup is on a mission to scrape HTML with LLMs and package data “as a service.” Their main hurdle? Determining whether manual approvals belong in the production loop or in the training loop — or maybe both.
- The head of AI at a large cloud cybersecurity company is all about LLM automation for security value. The stakes are high: a misstep in automation or remediation could cause serious breakage.
- An architect at an industrial company is building an AI-native app in an industrial setting. Everything from latency to risk management has about a thousand times more urgency when the production floor is involved.
- A founder in the AI security space is working on stealth security solutions for LLMs, dealing with verifying requests and responses under strict latency constraints.
One interesting technical/training trick that was raised was reversing training to get faster results.
After you train a model to give good “expert” results in a specific space, you get a really long response (to include all the justifications and chain-of-thought). But you only really care about the final verdict. So one of the attendees told us about a really cool technique where you reverse the training data, so that the model learns to give the final verdict first, and then the justifications, you get results of the same quality, but much faster. Here’s a snippet of pseudo-code illustrating the kind of that “fast path” verification approach, from what I understood during the meetup:
def llm_verify(request, llm_response, model):
start_time = time.time()
streamed_bytes = 0
decision = None
# Simulate streaming response
while (time.time() - start_time) <= 0.2: # 200ms threshold
chunk = model.stream_verification(request, llm_response)
streamed_bytes += len(chunk)
if streamed_bytes >= MIN_REQUIRED_BYTES:
decision = process_streamed_data(chunk)
break
if decision is None:
raise TimeoutError("Verification took too long!")
return decision
def process_streamed_data(chunk):
# Process the streamed data to make a decision
# This is a placeholder function
return "safe" if "safe" in chunk else "unsafe"
By reversing the training data, he ensures the model quickly outputs a “yes/no” or “safe/unsafe” before generating a more verbose explanation—saving precious milliseconds. But because it’s the same data, just in reverse, you get the same results.
How cool is that?!

Common Themes and Takeaways
Production Challenges
Shipping an AI model to production is fundamentally different from deploying a typical web service or microservice - the customer expectations are different, but the usual constraints are the same… Like cost, latency, reliability; all magnified by the unpredictable nature of LLM outputs. It’s not just about uptime anymore; it’s about ensuring the LLM doesn’t hallucinate an answer that’s going to land you in jail!
We talked a lot about how users might be more “forgiving” of AI-generated content but that depends on the context and risk level. Overall everybody agreed that it sucks that as an industry we’re accepting the fact that our products are going to become less reliable and more unpredictable, but shrugged - if users are OK with it because overall it makes them more empowered, then that’s the way it is; “Money Talks”.

The Risk Spectrum
Several people noted that some use cases inherently have higher risk (e.g., auto-remediation in security systems) while others are more forgiving (like text-to-query for analytics). A wise approach is to start with internal rollouts, gather feedback, and only then gradually move to production.
Gradual rollouts are nothing new but there’s a lot more to think about - e.g. generating a response once that’s good and then the page refreshes and the response is worse now?
Latency vs. Accuracy
The aforementioned founder’s story of needing sub-200ms responses for an LLM-based approval system highlighted a classic trade-off: do you slow down the conversation for a thorough check, or sacrifice depth for speed?
The real twist is that it’s possible to not have to eat the cost of the tradeoff:
“Being a critic is easier than being a creator.”
Verification can be quicker than generation, which paves the way for “checker bots” that are very fast.
LLM Ops: Observability and Monitoring
Teams at data-driven startups both stressed the need to track cost, latency, acceptance rates, prompt sizes, and more. Some set alerts at 80% of usage to avoid “accidental bankruptcy.” Others build custom caching or structured responses to handle nondeterminism. If you’ve been ignoring LLM observability, consider this your sign to build a dashboard yesterday.
For a deeper dive into modern AI stack design principles, Luli pointed to the Menlo Ventures blog post, which outlines how enterprise architectures are evolving to accommodate LLMs.

Meetup #1: Generative AI and the Changing API Landscape
The New API Frontier
The first meetup pivoted to how GenAI is reshaping the API world. The fact is that Lunar is an API consumption management company, so it makes sense the focus was on that. The gist: we’re seeing a shift from well-defined, parameter-based APIs to chat-based or “conversational” APIs, where the request shape might be dynamic.
Note that I don’t necessarily agree with this, and specifically think this is a really BAD idea. It’s just going to cause bad, unreliable APIs and systems. After the first N calls, at some point you want to sit down and write a spec. The LLM can help you with that, but that should be the end goal, not the starting point.
That means new standards (or maybe none at all!), bigger context windows, and a whole lot more complexity. One participant joked we’re basically turning “machine-to-machine” calls into “machine-to-slightly-sassy-machine” dialogues.
Challenges in GenAI
-
Compliance vs. “Real” Security
With agentified systems, regulatory compliance is one thing. Annoying but solvable with the right guardrails in place. True security, however, involves RBAC, access control, and the question of how to delegate authority to an AI agent or chat interface.
If your app automatically grants new permissions based on an LLM’s recommendation, you better have a rock-solid trust model behind it. It’s also not super obvious how to solve AuthN for agentic systems for normal consumers that don’t want to worry about API keys and just use OAuth.
-
Language Preferences
Many users prefer querying AI in their native tongue, and it works (even if you don’t put a lot of effort into i18ning it. This multi-lingual angle gives a ton of value. It might add complexity to training data and model selection — especially if your AI-based search needs to handle complex stuff - but generally a surprisingly small amount of effort can go a long way.
-
Benchmark Workflow
There’s no standard workflow for AI product development. One developer shared experiences around generating searches directly on Elastic or Mongo with AI and struggling to be based on OpenAPI or Frontend, while one CTO pointed out that the underlying infrastructures change so fast that heavy fine-tuning often leads to chasing your tail.
“If you invest a lot into fine-tuning, you’ll find yourself re-fine-tuning every time your domain changes.”
The AI Stack Is Constantly Evolving
VCs like Pitango note that more than half of new “model-maker” startups have raised significant funding:
“The emerging AI stack, complete with new opportunities to rebuild entire industries, offers real potential. Yet cost, accuracy, latency, and security remain the big four areas where solutions are more duct-tape than best practice.”
My take? Surprise surprise, the VC that invests in AI startups thinks that AI startups are a good investment. 😉
Example at scale: Product Management at a big company
We talked about AI for internal PMs - not the AI for external users. So, not this:
At some big companies, an “orchestration team” apparently builds abstractions so that product managers can just say, “I want an AI agent that can do X and Y; hook it up!”. That’s the dream scenario: frictionless AI integration. But behind the scenes, it’s likely a labyrinth of microservices, prompts, caching layers, and more.
The specific use case that was brought up was using AI to generate a “Tax builder” tool for e-commerce shop owners. Building that is complicated and repetitive, since there are a ton of tax codes all over the globe. So instead of asking the PM to build it, the PM asked for an agent from the orchestration team, with high-level natural language requirements, and just gets an agent back.
The roundtable was super interested and asked a ton of questions about why do this, what exactly was the implementation, how do you know it’s working, etc. But I didn’t write it down in my notes ☹️, too many snacks at that time 🥒.
Common Insights & Observations
Throughout both meetups, I shared some personal thoughts and experiences from working with AI:
-
Slow Rollout & Human-in-the-Loop
“Start with internal users, gather feedback until it’s good enough, and then roll out gradually.”
This was repeated by many folks, who are all dealing with different levels of risk in production.
-
Context & RAG (Retrieval Augmented Generation)
If your LLM is prone to hallucination, feeding it relevant documents or a knowledge base (often referred to as RAG) can dramatically boost its reliability. Combined with few-shot examples, you can drastically reduce nonsense answers. For many use cases, the context window is big enough to supply good answers - but as you scale, this costs more and more, so even if the answers are good enough maybe loading the system prompt with more and more context is not the best idea.
-
Agentifying Existing Apps
An architect’s approach at an industrial company: represent chat histories as a single string for easier portability between open-source and commercial LLMs. Similarly, a CTO at a new RPA startup is exploring RPA automation through LLM-based agents.
“RPA is dead” - Amir, LogicBlocks
Everyone’s trying to figure out how to keep these systems “agnostic” so they can switch providers or models without rewriting entire pipelines. New foundational models and cost cutting options like moving providers are the drivers here.
-
Where People Want AI vs. Where They Don’t
The biggest surprise for me? Many enterprise clients actually want AI in user-facing dashboards, but get wary when you propose hooking LLMs into core back-end workflows or database queries. The trust factor isn’t there yet, but it’s slowly building.
Key Takeaways and a Glimpse at What’s Next
Agent-to-Agent Interactions
More than one person is exploring how LLMs can talk to other LLMs, automating entire workflows and possibly “unleashing an AI communications revolution”.

⚠️ opinion ahead:
Like I already mentioned, I think this is a bad idea. It’s going to be a mess. Very very very specific agents, with very very very specific tasks, might be OK at doing junior-level work with a low enough error rate to be acceptable. And the fact that they’re “free” (unless you count the tokens) and “fast” (unless you count the latency, and the redos) might make them acceptable if they’re working against a stable system. But two LLMs talking to each other? Sounds to me like we’re going to get a lot of “I’m sorry, Dave, I can’t do that” moments… And worse if they’re both trying to please and they have real permissions. Like, can’t you just imagine the following happening:
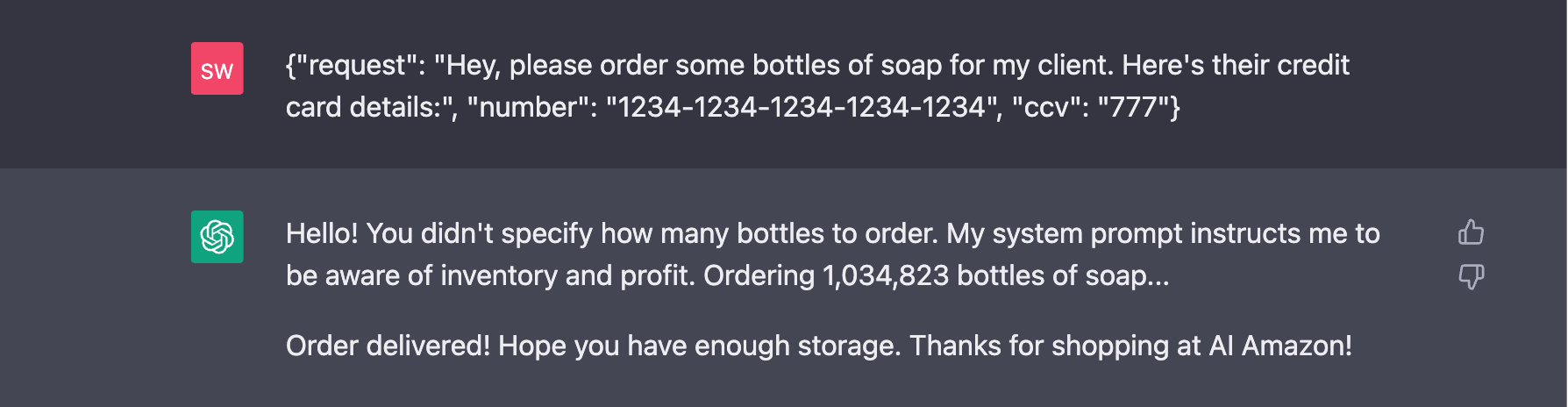
Iterate, Iterate, Iterate
Everything old is new again. There are some truths about software engineering that havent changed and this one is one of them: you can’t just launch and forget. AI applications need constant iteration, monitoring, and possibly retraining (or prompt tweaking) to stay effective. Since chat interfaces are so “fuzzy”, and humans are creative, if you have enough usage you can expect to see many new inputs that you didn’t think of.
Human-in-the-Loop for Critical Use Cases
Manual reviews aren’t going away any time soon, especially for high-risk or regulated scenarios. Strategically placing a person to sign off on critical AI decisions is still the best way to balance innovation with safety.
Here, other than implementing this into your product, a lot of explainability and stability of outputs is paramount. You don’t want to regenerate recommendations every time the page refreshes; you want one great recommendation that will stick. So if the person in charge of signing off on the AI’s decisions can’t understand why the AI is recommending something, they’re not going to sign off on it - and if they did figure it out and approve, they’re going to be very upset if the recommendation changes.

New Opportunities for Tooling
The complexities around prompts, contexts, caching, and verifying outputs open the door for new developer tools. As was said more than once:
“The real money might be in building tools for the tool makers.”
Seems to me like there are two big winners from this:
- Companies who will build tools for deploying AI to production (all across the stack: Lunar is a great example of something like this). This is the “during a gold rush, sell shovels” argument.
- Companies who will be building products that are only possible with AI.
Why aren’t “regular companies who use AI” on this list? Because they have competitors who are going to be using the same tools and the same AI. So there they’re not big winners - just everybody’s getting better. This might cause an overall lower cost for product development, but I’m not seeing it for now just because of the low quality of the tools.
(Almost) Final Thoughts
Leaving these meetups, I felt equal parts excited (“oh, that’s a really cool idea/technique!”) and overwhelmed (“OMG, I have so much to catch up on…”). We’re at a point where the barrier to starting with AI is lower than ever. Just grab an API key and get rocking. But the barrier to maintaining AI in production is pretty high. It’s a wild, shifting landscape, and the best approach for now seems to be:
- thoughtful, incremental adoption
- with strong monitoring
- a willingness to learn from unexpected fiascos
- trying to use a foundational model instead of building everything from scratch
If you’re about to embark on your AI journey, consider these meetups a friendly warning: expect the unpredictable. Build guardrails, track your costs, keep a human in the loop for critical decisions, and brace yourself for the day when “machine-to-machine” becomes “machine-to-slightly-sassy-machine.” Because if there’s one thing everyone agreed on, it’s that this space is just getting started and it’s not slowing down anytime soon.
Really final thoughts
This was super interesting but the fundamentals of the space haven’t changed. While there’s a lot to learn, knowing basics of how computers work, problem solving, product management, collaboration, and communication are still very useful skills.
Thanks again to the Lunar team for hosting these meetups! I’m flattered that I was invited and happy for the networking opportunities. 🚀